image sources: Upsplash
one data, many representations

image credit: Garrick Aden-Buie
Get data into tidy format

- pivot
pivot_longer()a wider-format data
library(tidyverse) # library(tidyr)tb %>% pivot_longer( cols = m_04:f_u, # cols in the data for pivoting names_to = "sex_age", # new col contains old headers values_to = "cases") # new col contains old values#> # A tibble: 115,380 x 4#> iso2 year sex_age cases#> <chr> <dbl> <chr> <dbl>#> 1 AD 1989 m_04 NA#> 2 AD 1989 m_514 NA#> 3 AD 1989 m_014 NA#> 4 AD 1989 m_1524 NA#> 5 AD 1989 m_2534 NA#> 6 AD 1989 m_3544 NA#> # … with 115,374 more rows
- pivot
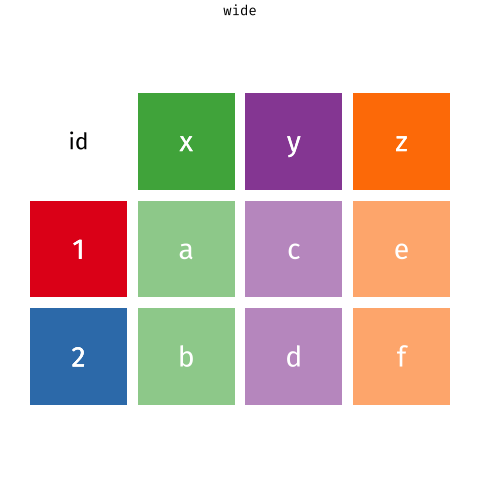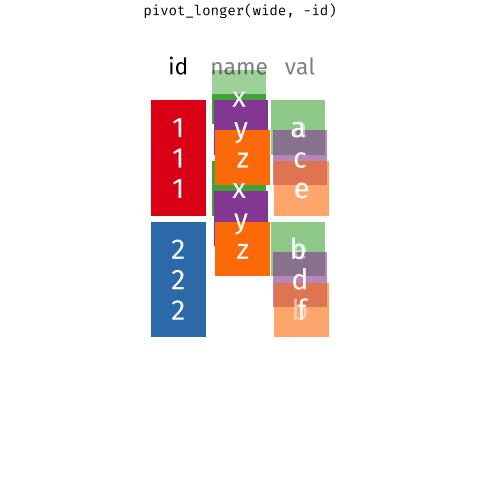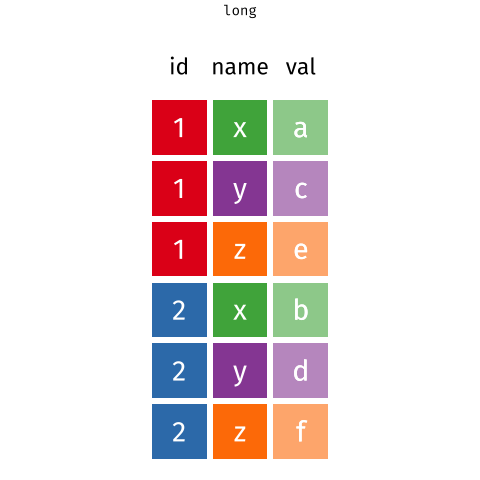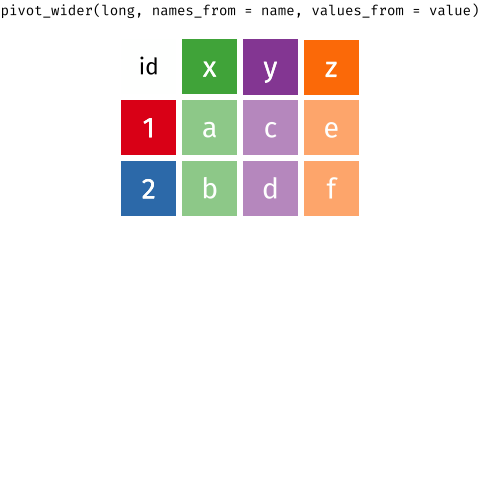
image credit: Garrick Aden-Buie & Mara Averick
- pivot
- split
seperate()a character column into multiple columns
tb %>% pivot_longer(cols = m_04:f_u, names_to = "sex_age", values_to = "cases") %>% separate(sex_age, into = c("sex", "age"), sep = "_")#> # A tibble: 115,380 x 5#> iso2 year sex age cases#> <chr> <dbl> <chr> <chr> <dbl>#> 1 AD 1989 m 04 NA#> 2 AD 1989 m 514 NA#> 3 AD 1989 m 014 NA#> 4 AD 1989 m 1524 NA#> 5 AD 1989 m 2534 NA#> 6 AD 1989 m 3544 NA#> # … with 115,374 more rows
- pivot
- split
- fill
fill()inNAwith previous ("down") or next ("up") value
tb_tidy <- tb %>% pivot_longer(cols = m_04:f_u, names_to = "sex_age", values_to = "cases") %>% separate(sex_age, into = c("sex", "age"), sep = "_") %>% group_by(iso2) %>% fill(cases, .direction = "updown") %>% ungroup()#> # A tibble: 115,380 x 5#> iso2 year sex age cases#> <chr> <dbl> <chr> <chr> <dbl>#> 1 AD 1989 m 04 0#> 2 AD 1989 m 514 0#> 3 AD 1989 m 014 0#> 4 AD 1989 m 1524 0#> 5 AD 1989 m 2534 0#> 6 AD 1989 m 3544 0#> # … with 115,374 more rows
- pivot
- split
- fill
- nest
nest()multiple columns into a list-column
tb_tidy %>% nest(data = -iso2)#> # A tibble: 213 x 2#> iso2 data #> <chr> <list> #> 1 AD <tibble[,4] [380 × 4]>#> 2 AE <tibble[,4] [520 × 4]>#> 3 AF <tibble[,4] [480 × 4]>#> 4 AG <tibble[,4] [540 × 4]>#> 5 AI <tibble[,4] [440 × 4]>#> 6 AL <tibble[,4] [540 × 4]>#> # … with 207 more rows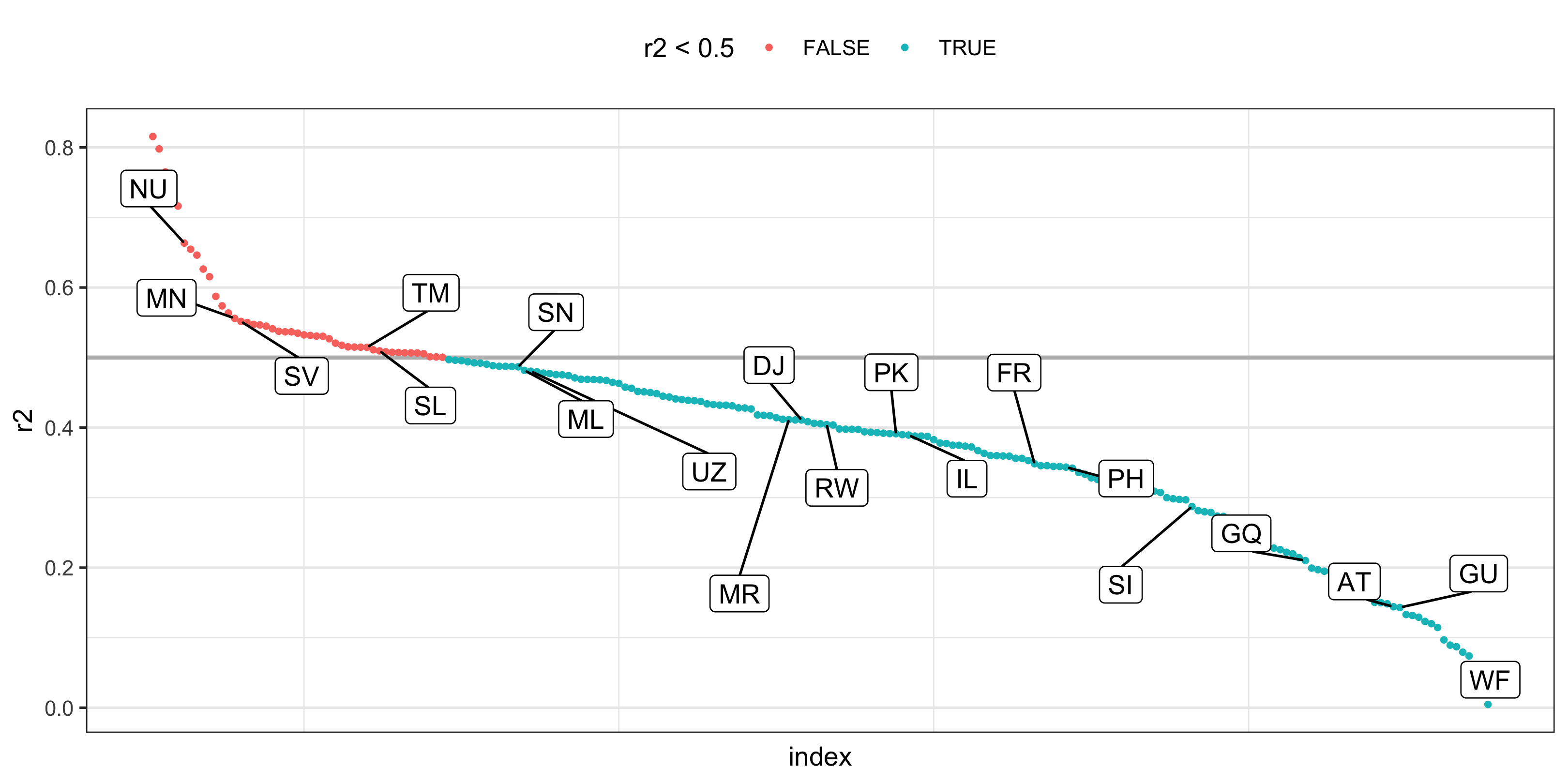
set.seed(220)tb_fit_pre <- tb_fit %>% arrange(-r2) %>% mutate(iso2 = fct_inorder(iso2), index = row_number())hl_tb <- tb_fit_pre %>% slice_sample(n = 20)tb_fit_pre %>% ggplot(aes(x = index, y = r2)) + geom_hline(yintercept = 0.5, size = 0.8, colour = "grey") + geom_point(aes(colour = r2 < 0.5), size = 0.8) + ggrepel::geom_label_repel(aes(label = iso2), data = hl_tb, box.padding = 1) + theme_bw() + theme( axis.text.x = element_blank(), axis.ticks.x = element_blank(), panel.grid.major.x = element_blank(), legend.position = "top" )
- calibrate
- calibrate the measurements
aklweather %>% mutate(value = value / 10)#> # A tibble: 2,974 x 3#> date datatype value#> <date> <chr> <dbl>#> 1 2019-01-01 PRCP 0 #> 2 2019-01-01 TAVG 20.6#> 3 2019-01-01 TMAX 23.2#> 4 2019-01-01 TMIN 18.8#> 5 2019-01-02 PRCP 0.5#> 6 2019-01-02 TAVG 20.7#> # … with 2,968 more rows
- calibrate
- pivot
pivot_wider()a longer-format data
aklweather %>% mutate(value = value / 10) %>% pivot_wider( names_from = datatype, # new headers from old `datatype` val values_from = value) # new col contains old `value`#> # A tibble: 816 x 5#> date PRCP TAVG TMAX TMIN#> <date> <dbl> <dbl> <dbl> <dbl>#> 1 2019-01-01 0 20.6 23.2 18.8#> 2 2019-01-02 0.5 20.7 23 18.3#> 3 2019-01-03 0 21.1 24.1 18.4#> 4 2019-01-04 0 19.2 22.9 NA #> 5 2019-01-05 0 20 23.3 15 #> 6 2019-01-06 0 21.3 23.7 16.9#> # … with 810 more rows
- calibrate
- pivot
- calibrate
- pivot
- rename
rename_with()renames columns using a function
aklweather_tidy <- aklweather %>% mutate(value = value / 10) %>% pivot_wider( names_from = datatype, values_from = value) %>% rename_with(tolower)aklweather_tidy#> # A tibble: 816 x 5#> date prcp tavg tmax tmin#> <date> <dbl> <dbl> <dbl> <dbl>#> 1 2019-01-01 0 20.6 23.2 18.8#> 2 2019-01-02 0.5 20.7 23 18.3#> 3 2019-01-03 0 21.1 24.1 18.4#> 4 2019-01-04 0 19.2 22.9 NA #> 5 2019-01-05 0 20 23.3 15 #> 6 2019-01-06 0 21.3 23.7 16.9#> # … with 810 more rows
- calibrate
- pivot
- rename
- complete
complete()data with missing combinations of data
library(lubridate)aklweather_tidy %>% complete(date = full_seq( ymd(c("2019-01-01", "2021-04-01")), 1))#> # A tibble: 822 x 5#> date prcp tavg tmax tmin#> <date> <dbl> <dbl> <dbl> <dbl>#> 1 2019-01-01 0 20.6 23.2 18.8#> 2 2019-01-02 0.5 20.7 23 18.3#> 3 2019-01-03 0 21.1 24.1 18.4#> 4 2019-01-04 0 19.2 22.9 NA #> 5 2019-01-05 0 20 23.3 15 #> 6 2019-01-06 0 21.3 23.7 16.9#> # … with 816 more rows
- calibrate
- pivot
- rename
- complete
- implicit missing records before
aklweather_tidy %>% complete(date = full_seq( ymd(c("2019-01-01", "2021-04-01")), 1)) %>% anti_join(aklweather_tidy)#> # A tibble: 6 x 5#> date prcp tavg tmax tmin#> <date> <dbl> <dbl> <dbl> <dbl>#> 1 2019-02-16 NA NA NA NA#> 2 2019-02-17 NA NA NA NA#> 3 2019-02-18 NA NA NA NA#> 4 2021-02-11 NA NA NA NA#> 5 2021-02-12 NA NA NA NA#> 6 2021-02-20 NA NA NA NA
- calibrate
- pivot
- rename
- complete
- wrangle
akl_prcp <- aklweather_tidy %>% complete( date = full_seq(ymd(c("2019-01-01", "2021-04-01")), 1), fill = list(prcp = 0) ) %>% group_by(yearmonth = floor_date(date, "1 month")) %>% mutate(cum_prcp = cumsum(prcp)) %>% ungroup()akl_prcp#> # A tibble: 822 x 7#> date prcp tavg tmax tmin yearmonth cum_prcp#> <date> <dbl> <dbl> <dbl> <dbl> <date> <dbl>#> 1 2019-01-01 0 20.6 23.2 18.8 2019-01-01 0 #> 2 2019-01-02 0.5 20.7 23 18.3 2019-01-01 0.5#> 3 2019-01-03 0 21.1 24.1 18.4 2019-01-01 0.5#> 4 2019-01-04 0 19.2 22.9 NA 2019-01-01 0.5#> 5 2019-01-05 0 20 23.3 15 2019-01-01 0.5#> 6 2019-01-06 0 21.3 23.7 16.9 2019-01-01 0.5#> # … with 816 more rows
- calibrate
- pivot
- rename
- complete
- wrangle
- visualise
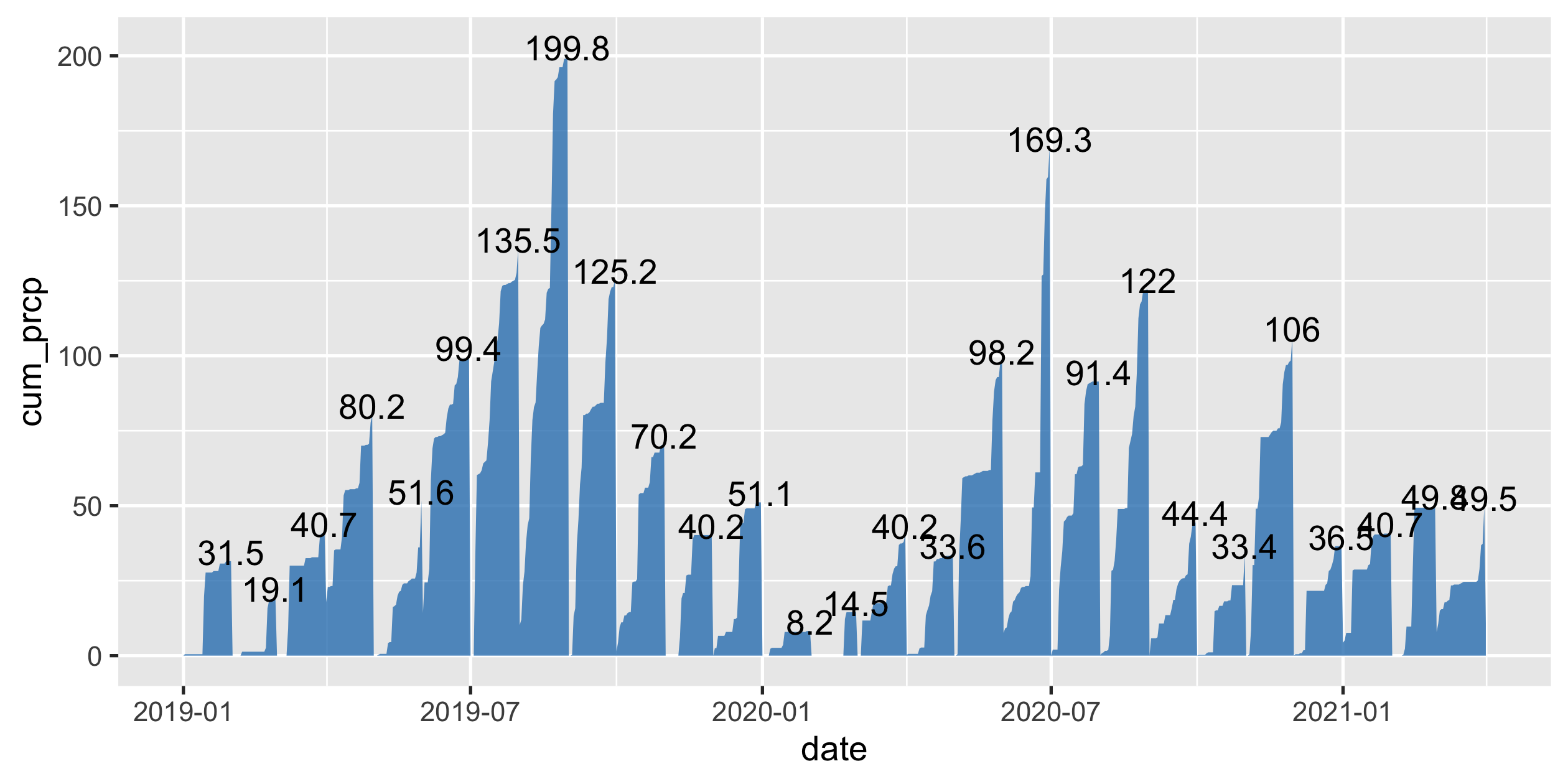
- calibrate
- pivot
- rename
- complete
- wrangle
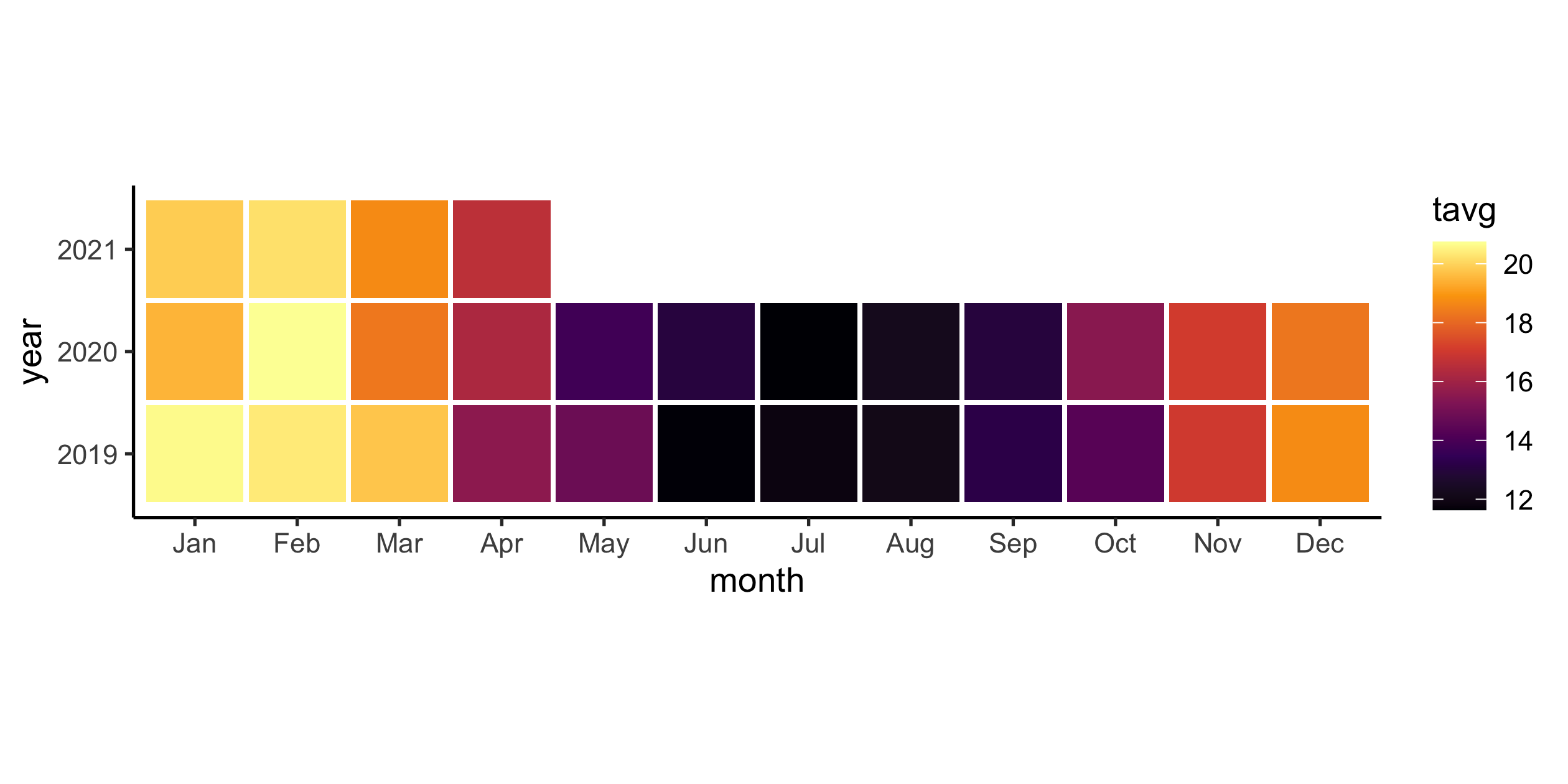
akl_monthly_temp <- aklweather_tidy %>% group_by(yearmonth = floor_date(date, "1 month")) %>% summarise( tavg = mean(tavg, na.rm = TRUE), tmax = mean(tmax, na.rm = TRUE), tmin = mean(tmin, na.rm = TRUE) )akl_monthly_temp#> # A tibble: 28 x 4#> yearmonth tavg tmax tmin#> <date> <dbl> <dbl> <dbl>#> 1 2019-01-01 20.6 24.4 17.3 #> 2 2019-02-01 20.4 25.2 16.1 #> 3 2019-03-01 19.7 24.5 15.6 #> 4 2019-04-01 15.6 20.0 10.5 #> 5 2019-05-01 14.8 18.9 10.2 #> 6 2019-06-01 11.7 15.4 7.62#> # … with 22 more rows