
- create
Fixed pattern
Create strings with ' or "
library(tidyverse) # library(stringr)string <- "lzDHk3orange2o5ghte"string#> [1] "lzDHk3orange2o5ghte"fruit <- c("cherry", "banana")fruit#> [1] "cherry" "banana"
- create
- join
Fixed pattern
Join strings
c(string, fruit)#> [1] "lzDHk3orange2o5ghte" "cherry" "banana"str_c(string, fruit, sep = ", ")#> [1] "lzDHk3orange2o5ghte, cherry" "lzDHk3orange2o5ghte, banana"str_c(string, fruit, collapse = ", ")#> [1] "lzDHk3orange2o5ghtecherry, lzDHk3orange2o5ghtebanana"
- create
- join
- detect
Fixed pattern
Determine which strings match a pattern
str_detect(string, "orange")#> [1] TRUEstr_detect(fruit, "orange")#> [1] FALSE FALSE
- create
- join
- detect
- locate
Fixed pattern
Find the positions of matches
str_locate(string, "orange")#> start end#> [1,] 7 12str_locate(fruit, "orange")#> start end#> [1,] NA NA#> [2,] NA NA
- create
- join
- detect
- locate
- extract
Fixed pattern
Extract the content of matches
str_sub(string, 7, 12)#> [1] "orange"str_extract(string, "orange")#> [1] "orange"str_extract(fruit, "orange")#> [1] NA NA
- create
- join
- detect
- locate
- extract
- replace
Fixed pattern
Replace matches with new values
str_replace(string, "orange", "apple")#> [1] "lzDHk3apple2o5ghte"str_replace(fruit, "orange", "apple")#> [1] "cherry" "banana"
- period
Regex
. matches any character (except a newline)
str_extract(string, "o....e")#> [1] "orange"str_extract_all(string, "o....e")#> [[1]]#> [1] "orange" "o5ghte"
- period
- qualifier
Regex
repetition
str_extract_all(string, "o.{4}e")#> [[1]]#> [1] "orange" "o5ghte"str_extract_all(string, "o.*e")#> [[1]]#> [1] "orange2o5ghte"str_extract_all(string, "o.*?e")#> [[1]]#> [1] "orange" "o5ghte"
- period
- qualifier
Regex
repetition
?: 0 or 1+: 1 or more*: 0 or more{n}: exactly n{n,}: n or more{,m}: at most m{n,m}: between n and m
- period
- qualifier
- escape
Regex
if . matches any character, how to match a literal "."?
- use the backslash
\to escape special behaviour\. \is also used as an escape symbol in strings- end up using
"\\."to create the regular expression\.
str_view_all(string, "o\\.{4}e")str_view_all("a.b.c", "\\.")
- period
- qualifier
- escape
- meta
Regex
\d: matches any digit. (metacharacter)\s: matches any whitespace (e.g. space, tab\t, newline\n).[abc]: matches a, b, or c. (make character classes by hand)
str_view_all(string, "\\d")str_view_all(string, "[0-9]")
- period
- qualifier
- escape
- meta
Regex
\D: matches anything except digits.\S: matches anything except whitespaces.[^abc]: matches anything except a, b, or c.
str_view_all(string, "\\D")str_view_all(string, "[^0-9]")
- period
- qualifier
- escape
- meta
- POSIX
Regex
[:digit:]: matches any digit.[:space:]: matches any whitespace.[:alpha:]: matches any alphabetic character.- more on ?base::regex
str_view_all(string, "[:digit:]")str_view_all(string, "[:alpha:]")
- period
- qualifier
- escape
- meta
- POSIX
- anchor
Regex
^matches the start of the string.$matches the end of the string.
str_view_all(fruit, "a")str_view_all(fruit, "a$")str_view_all(fruit, "^a")
- tokenise
unigram
library(tidytext)text_tbl %>% unnest_tokens(output = word, input = text)#> # A tibble: 49 x 2#> line word #> <int> <chr> #> 1 1 this #> 2 1 will #> 3 1 be #> 4 1 an #> 5 1 uncertain#> 6 1 time #> # … with 43 more rows
- tokenise
unigram
text_tbl %>% unnest_tokens(output = word, input = text) %>% count(word, sort = TRUE)#> # A tibble: 32 x 2#> word n#> <chr> <int>#> 1 my 7#> 2 love 5#> 3 i 3#> 4 your 3#> 5 can 2#> 6 in 2#> # … with 26 more rowshow often we see each word in this corpus
- tokenise
letters
text_tbl %>% unnest_characters(output = word, input = text)#> # A tibble: 171 x 2#> line word #> <int> <chr>#> 1 1 t #> 2 1 h #> 3 1 i #> 4 1 s #> 5 1 w #> 6 1 i #> # … with 165 more rows
- tokenise
n-gram
text_tbl %>% unnest_ngrams(output = word, input = text, n = 2)#> # A tibble: 43 x 2#> line word #> <int> <chr> #> 1 1 this will #> 2 1 will be #> 3 1 be an #> 4 1 an uncertain #> 5 1 uncertain time#> 6 1 time for #> # … with 37 more rows
sentiment analysis
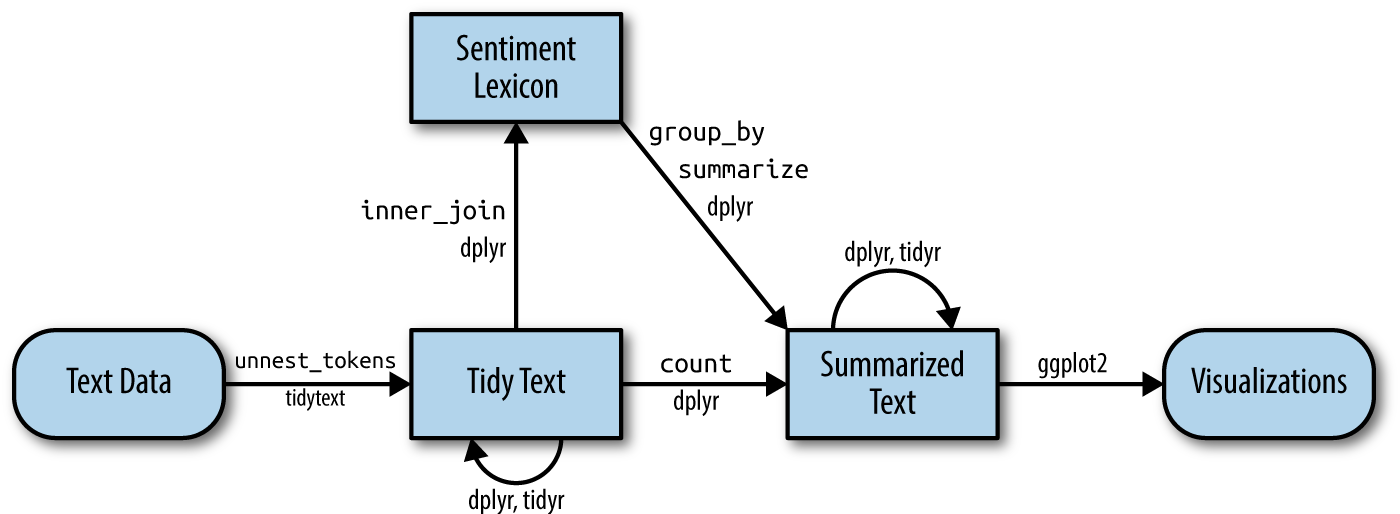 image credit: Text Mining with R
image credit: Text Mining with R
- import
sentiment analysis
user_reviews <- read_tsv( "data/animal-crossing/user_reviews.tsv")user_reviews#> # A tibble: 2,999 x 4#> grade user_name text date #> <dbl> <chr> <chr> <date> #> 1 4 mds27272 My gf started playing before… 2020-03-20#> 2 5 lolo2178 While the game itself is gre… 2020-03-20#> 3 0 Roachant My wife and I were looking f… 2020-03-20#> 4 0 Houndf We need equal values and opp… 2020-03-20#> 5 0 ProfessorF… BEWARE! If you have multipl… 2020-03-20#> 6 0 tb726 The limitation of one island… 2020-03-20#> # … with 2,993 more rows
- import
- glimpse
grade distribution
user_reviews %>% ggplot(aes(grade)) + geom_bar()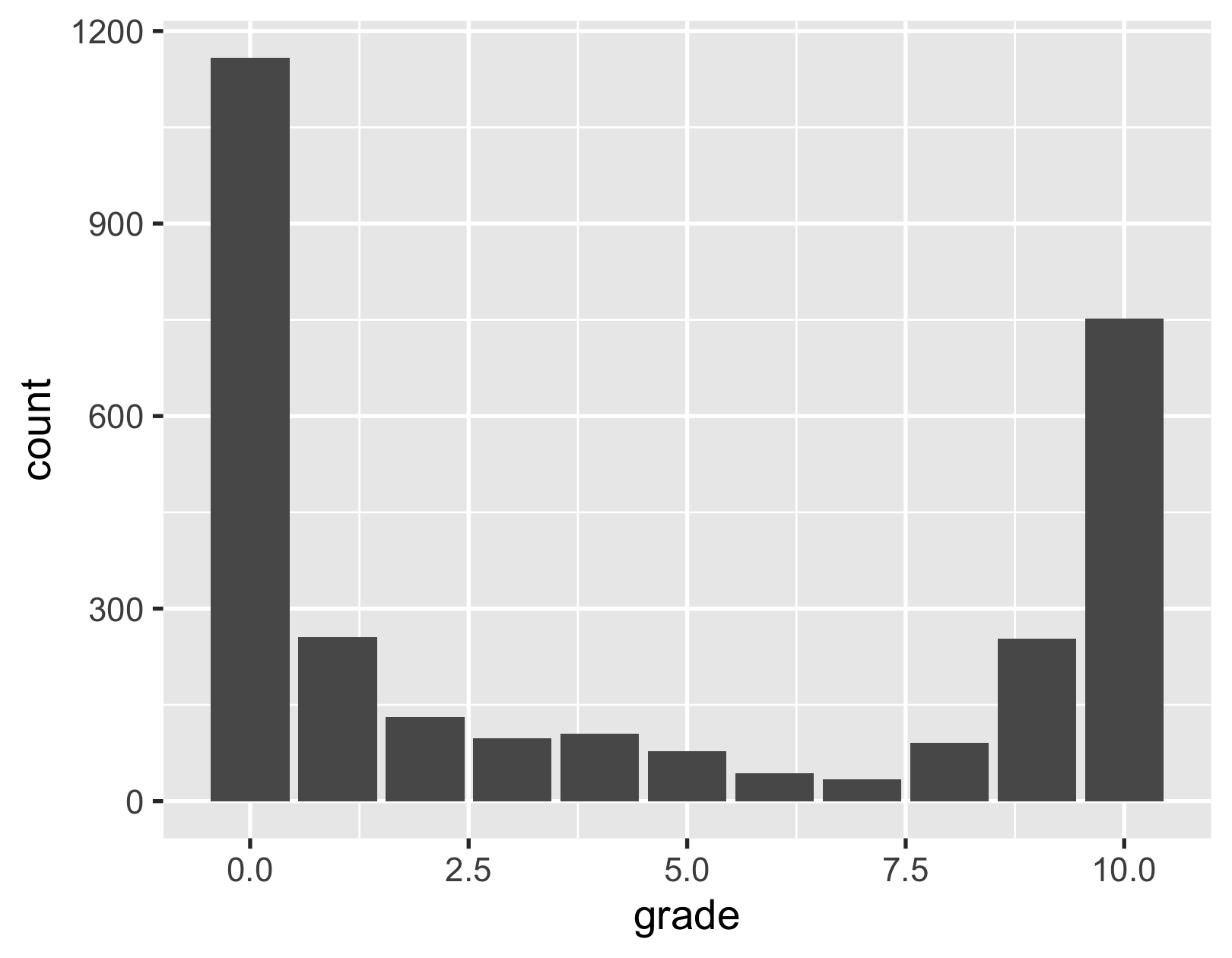
- import
- glimpse
positive vs negative reviews
user_reviews %>% slice_max(grade, with_ties = FALSE) %>% pull(text)#> [1] "Cant stop playing!"user_reviews %>% slice_min(grade, with_ties = FALSE) %>% pull(text)#> [1] "My wife and I were looking forward to playing this game when it released. I bought it, I let her play first she made an island and played for a bit. Then I decided to play only to discover that Nintendo only allows one island per switch! Not only that, the second player cannot build anything on the island and tool building is considerably harder to do. So, if you have more than one personMy wife and I were looking forward to playing this game when it released. I bought it, I let her play first she made an island and played for a bit. Then I decided to play only to discover that Nintendo only allows one island per switch! Not only that, the second player cannot build anything on the island and tool building is considerably harder to do. So, if you have more than one person in your home that wants to play the game, you need two switches. Worst decision I have ever seen, this even beats EA.Congratulations Nintendo, you have officially become the worst video game company this year!… Expand"
- import
- glimpse
- tokenise
clean a bit from web scraping ...
user_reviews_words <- user_reviews %>% mutate(text = str_remove(text, "Expand$")) %>% unnest_tokens(output = word, input = text)user_reviews_words#> # A tibble: 362,729 x 4#> grade user_name date word #> <dbl> <chr> <date> <chr> #> 1 4 mds27272 2020-03-20 my #> 2 4 mds27272 2020-03-20 gf #> 3 4 mds27272 2020-03-20 started#> 4 4 mds27272 2020-03-20 playing#> 5 4 mds27272 2020-03-20 before #> 6 4 mds27272 2020-03-20 me #> # … with 362,723 more rows
- import
- glimpse
- tokenise
- vis
distribution of words per review
user_reviews_words %>% count(user_name) %>% ggplot(aes(x = n)) + geom_histogram()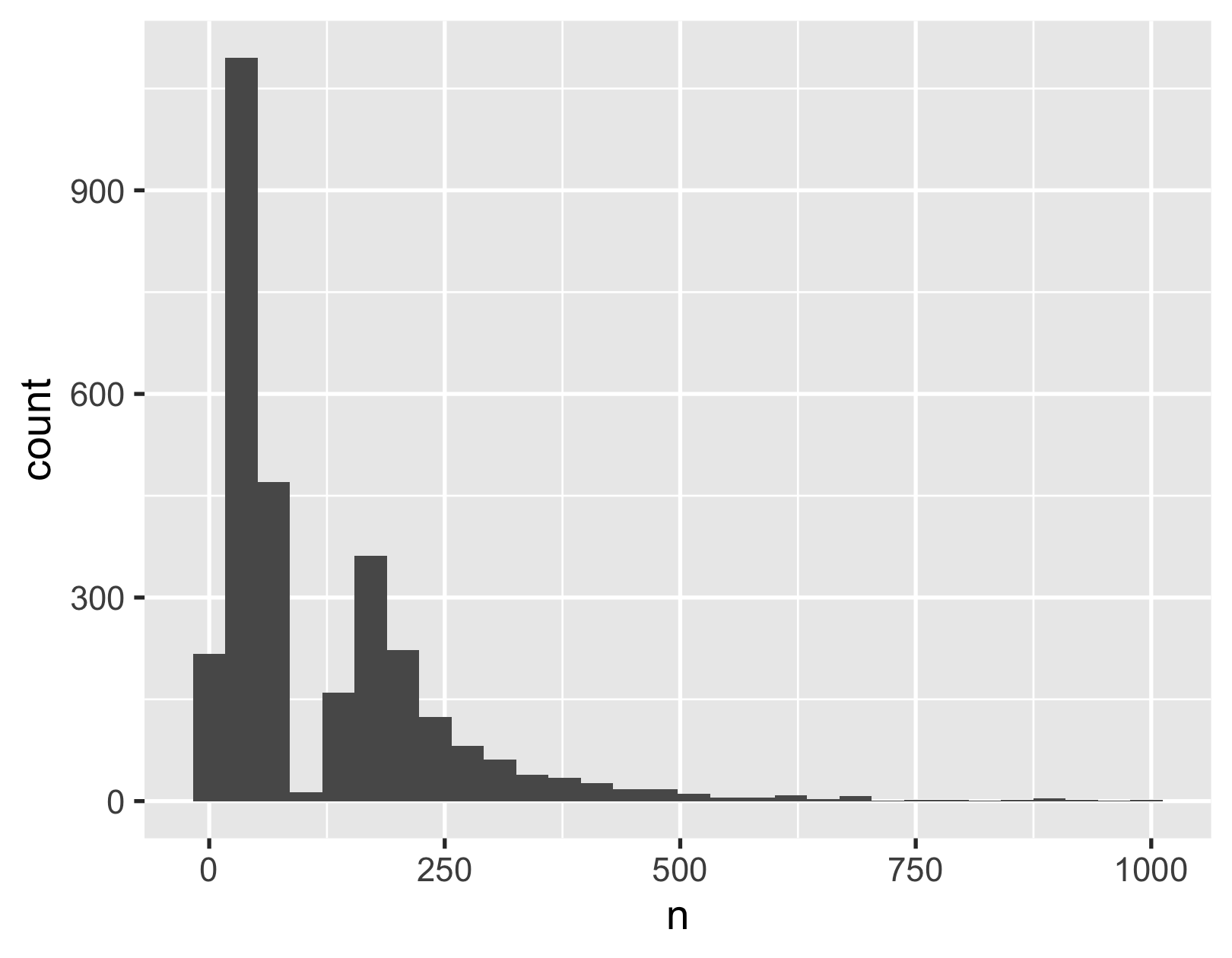
- import
- glimpse
- tokenise
- vis
- stop words
the most common words
user_reviews_words %>% count(word, sort = TRUE)#> # A tibble: 13,454 x 2#> word n#> <chr> <int>#> 1 the 17739#> 2 to 11857#> 3 game 8769#> 4 and 8740#> 5 a 8330#> 6 i 7211#> # … with 13,448 more rows
- import
- glimpse
- tokenise
- vis
- stop words
lexicon
get_stopwords()#> # A tibble: 175 x 2#> word lexicon #> <chr> <chr> #> 1 i snowball#> 2 me snowball#> 3 my snowball#> 4 myself snowball#> 5 we snowball#> 6 our snowball#> # … with 169 more rows- In computing, stop words are words which are filtered out before or after processing of natural language data (text).
- They usually refer to the most common words in a language, but there is not a single list of stop words used by all natural language processing tools.
- import
- glimpse
- tokenise
- vis
- stop words
remove stop words
stopwords_smart <- get_stopwords(source = "smart")user_reviews_smart <- user_reviews_words %>% anti_join(stopwords_smart)user_reviews_smart#> # A tibble: 145,444 x 4#> grade user_name date word #> <dbl> <chr> <date> <chr> #> 1 4 mds27272 2020-03-20 gf #> 2 4 mds27272 2020-03-20 started#> 3 4 mds27272 2020-03-20 playing#> 4 4 mds27272 2020-03-20 option #> 5 4 mds27272 2020-03-20 create #> 6 4 mds27272 2020-03-20 island #> # … with 145,438 more rows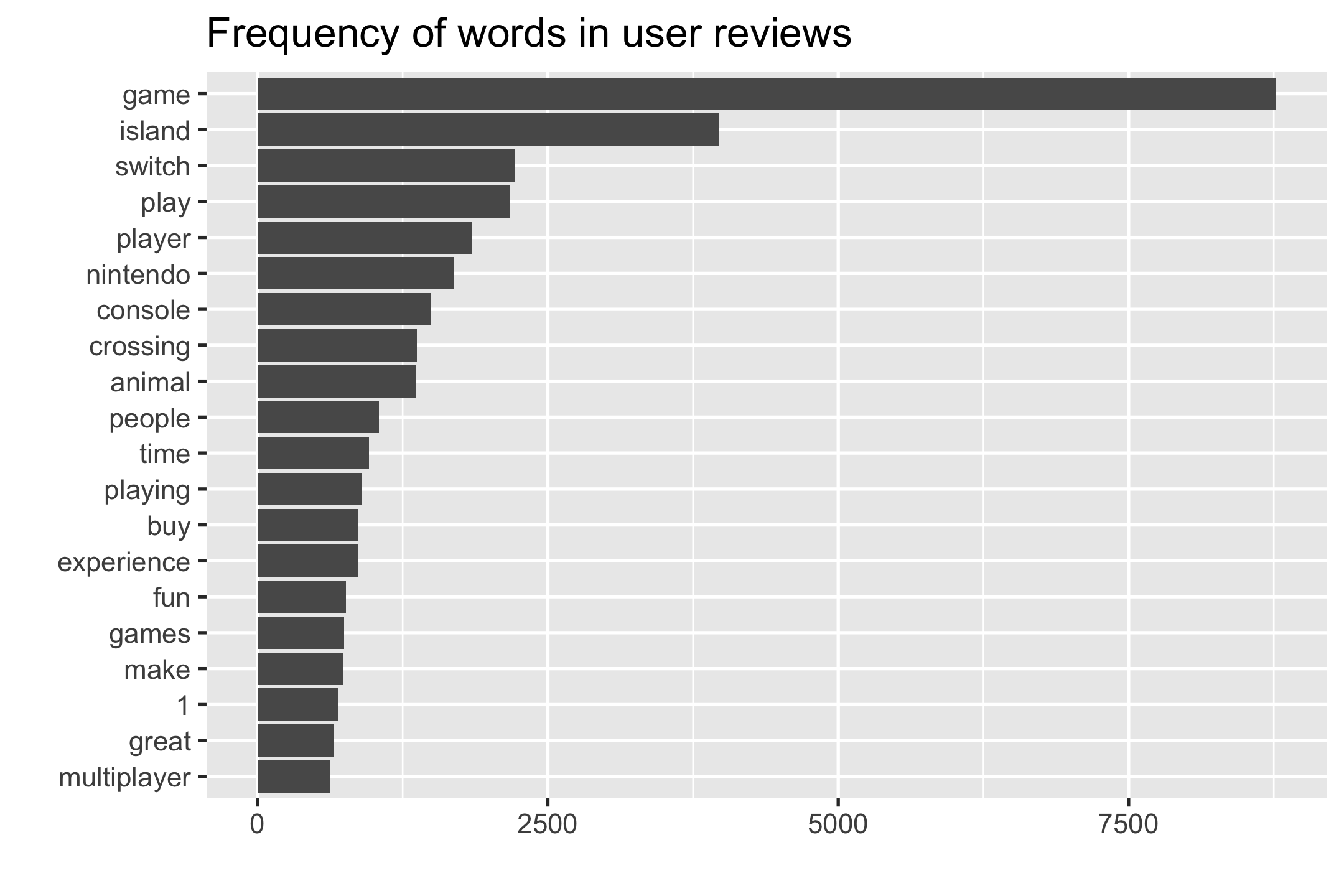
- import
- glimpse
- tokenise
- vis
- stop words
- count
- sentiments
sentiment lexicons
- AFINN lexicon measures sentiment with a numeric score b/t -5 & 5.
get_sentiments("afinn")#> # A tibble: 2,477 x 2#> word value#> <chr> <dbl>#> 1 abandon -2#> 2 abandoned -2#> 3 abandons -2#> 4 abducted -2#> 5 abduction -2#> 6 abductions -2#> # … with 2,471 more rows- Other lexicons categorise words in a binary fashion, either positive or negative.
get_sentiments("loughran")#> # A tibble: 4,150 x 2#> word sentiment#> <chr> <chr> #> 1 abandon negative #> 2 abandoned negative #> 3 abandoning negative #> 4 abandonment negative #> 5 abandonments negative #> 6 abandons negative #> # … with 4,144 more rows
- import
- glimpse
- tokenise
- vis
- stop words
- count
- sentiments
sentiment lexicons
sentiments_bing <- get_sentiments("bing")sentiments_bing#> # A tibble: 6,786 x 2#> word sentiment#> <chr> <chr> #> 1 2-faces negative #> 2 abnormal negative #> 3 abolish negative #> 4 abominable negative #> 5 abominably negative #> 6 abominate negative #> # … with 6,780 more rows
- import
- glimpse
- tokenise
- vis
- stop words
- count
- sentiments
join sentiments
user_reviews_sentiments <- user_reviews_words %>% inner_join(sentiments_bing) %>% count(sentiment, word, sort = TRUE)user_reviews_sentiments#> # A tibble: 1,622 x 3#> sentiment word n#> <chr> <chr> <int>#> 1 positive like 1357#> 2 positive fun 760#> 3 positive great 661#> 4 positive progress 556#> 5 positive good 486#> 6 positive enjoy 405#> # … with 1,616 more rows
- import
- glimpse
- tokenise
- vis
- stop words
- count
- sentiments
- vis
visualise sentiments
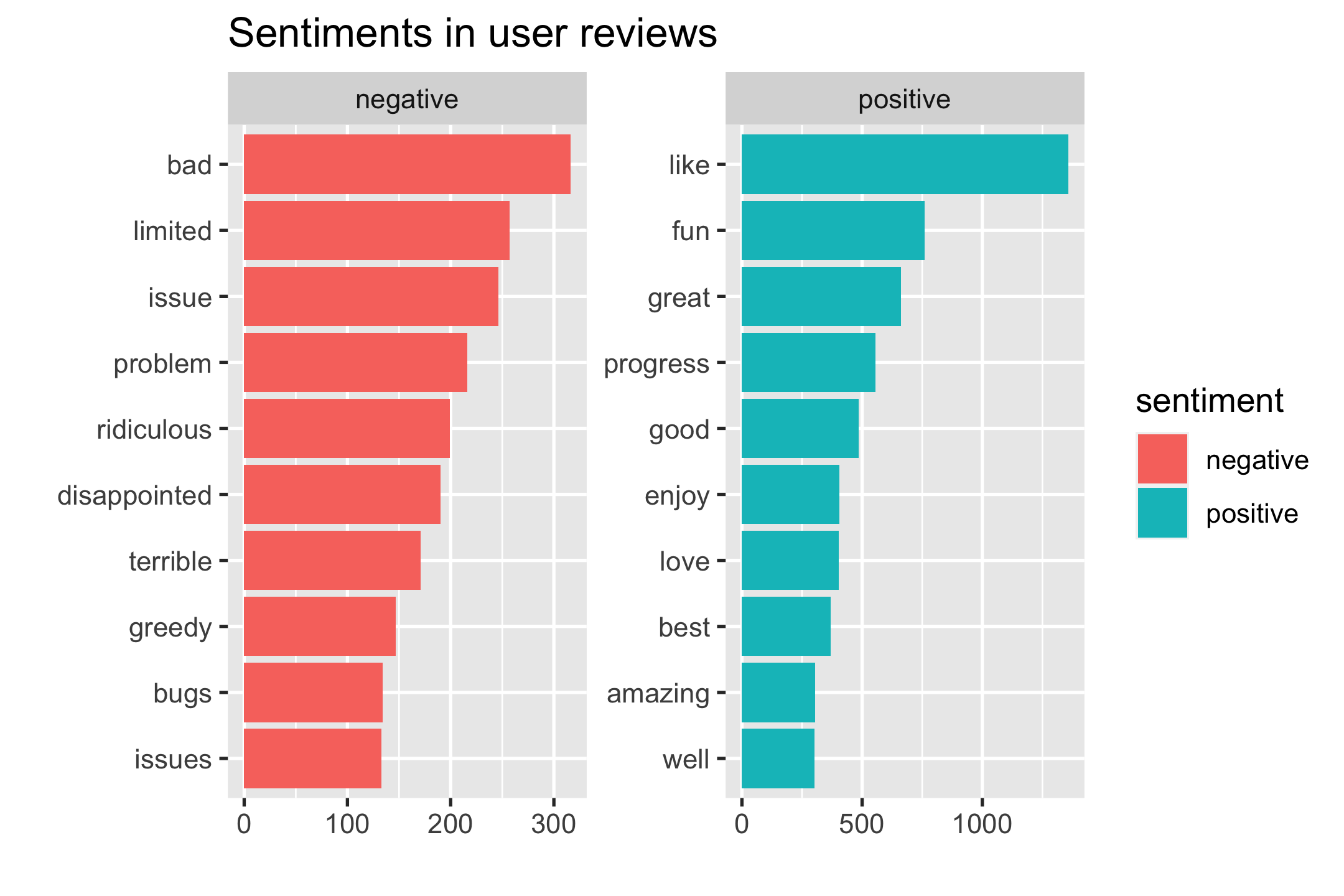
- import
- glimpse
- tokenise
- vis
- stop words
- count
- sentiments
- vis
Would Animal Crossing be considered to be a delightful game?
user_reviews_sentiments %>% group_by(sentiment) %>% summarise(n = sum(n)) %>% mutate(p = n / sum(n))#> # A tibble: 2 x 3#> sentiment n p#> <chr> <int> <dbl>#> 1 negative 11097 0.464#> 2 positive 12825 0.536
